Scatter plot
scatter (산점도)는 수치와 수치를 비교할때 사용한다. 즉, float, float를 비교한다 생각하면 좋을거 같다.
초보자가 가끔하는 어뚱한짓은 x축이나 y축을 int, 카테고리 컬럼등등을 써서 비교하는 경우가 있는데 이는 아마도 이상한 모양이 나올 확률이 높다.
다시 말해서 scatter plot은 두변수가 수치형일경우 적합한 차트라고 이해하면 좋을거 같다.
하지만 scatter의 차트 기능을 통해 수치형을 비교후 범주형(카테고리)데이터를 비교분석 할 수 있다.
아래에서 편의상 scatterplot과 relplot을 혼횽했지만 둘다 scatter를 표현하는 차트라고 이해하면 된다. relplot은 scatter기능에서 추가로 카테고리별 차트기능을 그려주는데 이는 이번 실습과 무관하기 때문에 같다고 보면 됩니다.
Data 로드
- 우선 필요한 패키지와 모듈을 import합니다
import numpy as np import pandas as pd from matplotlib import style import matplotlib.pyplot as plt import seaborn as sns style.use('ggplot') or plt.style.use('ggplot') plt.style.use('fivethirtyeight')- seaborn에서 제공하는 tips이란 데이터 셋을 로드 합니다. 물론 판다스 형식입니다.
- 그리고 데이터가 정상적으로 로드되었는지 확인차 상위5개 데이터를 확인해 봅니다.
tips = sns.load_dataset("tips") tips.head(5)
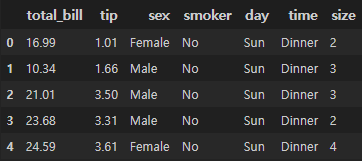
Data 확인
- 데이터를 로드후에 가장먼저 해야하는 일은 어떤 데이터를 어떻게 시각화할지 고민해봐야 합니다.
- 그러기 위해선 어떤 컬럼이 어떤 성격을 가지고 있는지, 또는 어떤 분포를 가지고 있는기 고민해봐야 합니다.
- info 정보를 보시면 데이터의 크기오 각컬럼의 type들을 알수 있습니다.
tips.info()
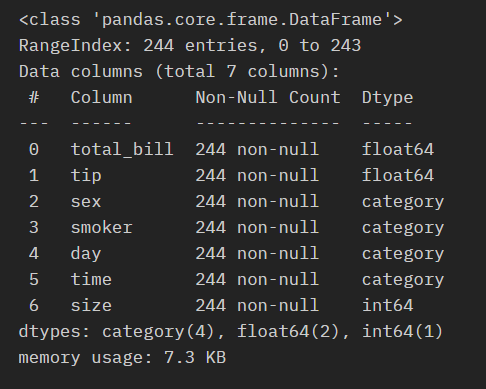
- info 정보를 확인해 보니 total_bill, tip, size는 float64 인걸보니 수치형 데이터이고 나머지는 category형 데이터 입니다.
- category타입은 object와 비슷하나 카테고리 값이 순서를 갖고 있는것이 다르다고 할수 있습니다.
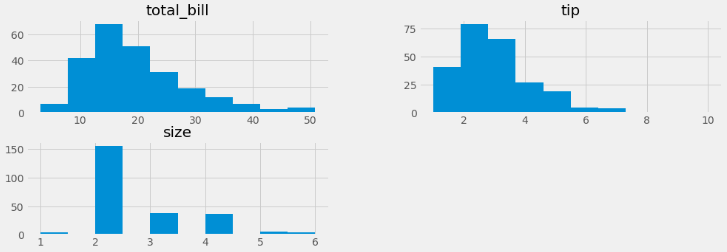
- 우선 수치형 데이터의 히스토그램을 확인해 봅시다.
- 히스토그램의 데이터의 밀집 정도를 차트로 보여줍니다.
tips[['total_bill','tip', 'size']].hist(bins=10, figsize=(15,5))
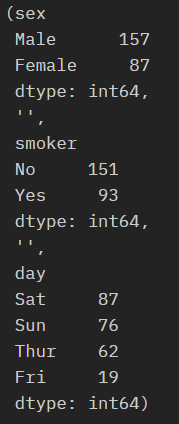
- 나머지 category형 타입의 데이터의 종류들을 확인해 봅시다.
tips.value_counts('sex'),'',tips.value_counts('smoker'),'',tips.value_counts('day')
데이터 시각화
scatter
- 우선 위에서 확인한 total_bill과 tip간에 상관도를 scatter차트를 이요해서 확인해 봅시다.
plt.figure(figsize=(8,8)) sns.scatterplot(x="total_bill", y="tip", data=tips);
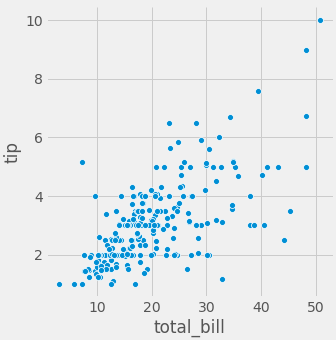
- 보시다 싶이 총 지불금액이 높아질수록 tip을 주는 금액에 커지는것을 한눈에 알수 있습니다.
- 이런것이 데이터 시각화의 매력이라고 할 수 있습니다.
Scatter 카테고리별 확인 (hue)
- 그럼 좀더 다양한 데이터를 확인하기 위해 수치형과 범주형 데이터를 같이 보겠습니다.
- 아래에선 hue를 통해서 total_bill과 tip간에 산포도에서 smoker에 따라서 색을 다르게 표시 했습니다.
- 흡연자와 비흡연자의 관계가 잘 보이지 않을 수 있어서 제가 따로 차트로 분리하여 그렸습니다.
sns.relplot(x="total_bill", y="tip", hue='smoker', data=tips); sns.relplot(x="total_bill", y="tip", data=tips[tips['smoker']== 'Yes'], color='r') sns.relplot(x="total_bill", y="tip", data=tips[tips['smoker']== 'No'], color='b')
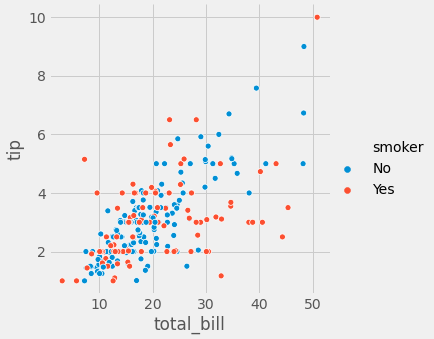
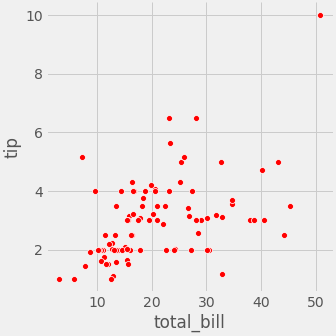
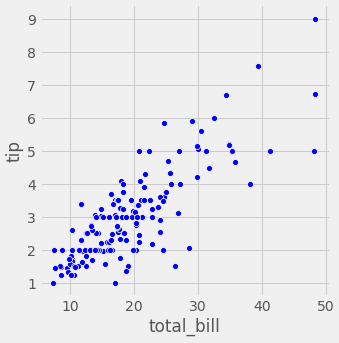
- 결과를 보시면 흡연자일 수록 tip에 대해서 보수적인 성향을 볼수 있습니다.
- 왜 그런지가 중요합니다만, 여기선 그런것들을 파악하기 보단 차트를 표현하는데 중점을 두겠습니다.
- 하지만, 운영에선 왜 흡연자가 tip에대해서 보수적인지가 아주 중요한 단서가 될수 있기 때문에 파악으 해보는것이 좋겠죠
Scatter Marker Stype
- 런치와 디너 즉, 점심과 저녁을 함께 표현하겠습니다.
- 여기선 style로 표현을 했는데 style은 marker모양을 다르게 표시해주는것이 특징입니다.
- 아래서 보시면 x가 런치, o가 디너 입니다. 확실히 디너에 tip과 total_bill이 낮은걸 볼수 있습니다.
- 이는 런치 셋트나 점심이니 간단하게 먹고갈수 있어서 그런것으로 보입니다.
plt.figure(figsize=(12,12))
sns.scatterplot(x="total_bill", y="tip", hue='smoker', style='time', data=tips);
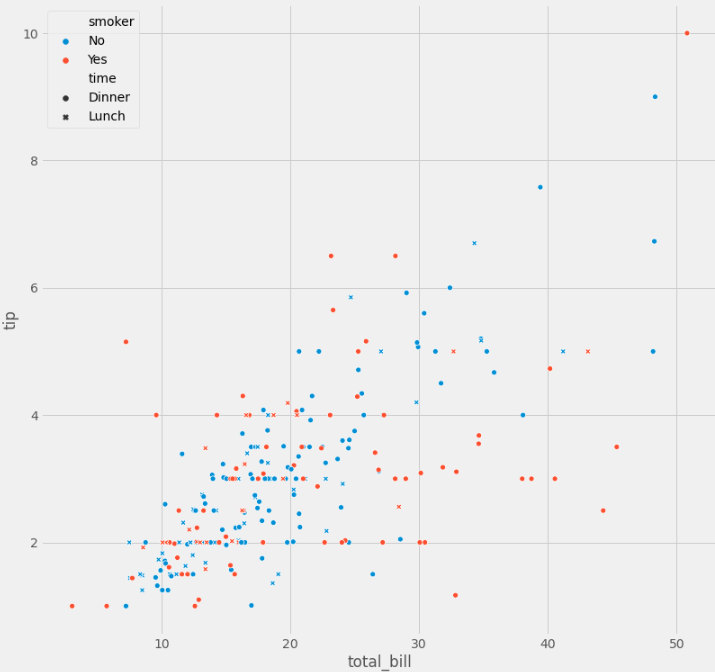
Scatter 수치형 구분
- 이번에 hue에 smoker가 아닌 size를 넣어 봅시다 아마 아까와 다른 형태의 색과 차트, legend를 확인할 수 있습니다.
- 이는 matplotlib에서 자동으로 hue에 어떤값이 들어오는지 확인하여 적절한 표의 형태를 만들어 줍니다.
- 아래에선 사이즈가 클수록 색이 진해지는 것을 볼수 있습니다.
sns.scatterplot(x="total_bill", y="tip", hue="size", data=tips);
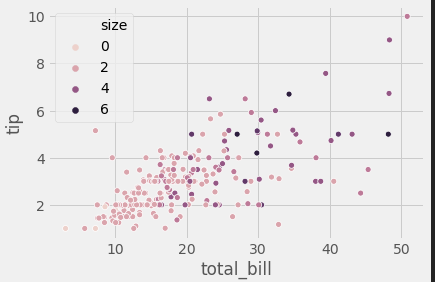
Scatter Point Size
- 마지막으로 size를 넣어 보겠습니다. size는 산점도의 점의 크기를 다르게 표현해 줍니다. sizes를 통해서 점의 크기를 정의할 수 있습니다.
sns.relplot(x="total_bill", y="tip", size="size", sizes=(1, 500), data=tips);
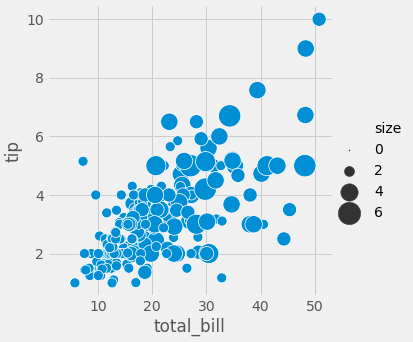
seaborn의 scatter plot은 제가 가장 좋아하는 시각화 방법입니다.
이유는 데이터를 그렸을때 데이터의 분포 및 여러 형태를 가장 잘 분석할 수 있기 때문입니다.
나중에 머신러닝이나 딥러닝쪽으로 공부한다면 scatter를 많이 아셔야 수월하게 데이터 분석 및 학습을 진행할 수 있습니다.
scatter는 위의 기능말고도 더 많은 기능이 있으나 제가 말하고자 하는건 scatter는 수치형과 수치형을 비교할때 쓰입니다. 이걸 전달해 드리고 싶었습니다. 저도 초보때 카테고리형 컬럼을 x축에 놓고 이상한 모양의 차트를 그려놓고 많이 혼란스러워 했습니다. ㅠㅠ
이글을 읽고 부디 scatter차트에 대해서 조금더 이해하셨으면 다행입니다.
감사합니다.!
'[개발] 이야기' 카테고리의 다른 글
| python 기술적 지표 구현해 보기(2) [count, mean, std 구현하기] (0) | 2020.09.14 |
|---|---|
| python 기술적 지표 구현해 보기(1) [Describe, 평균, 분산, 사분위] (0) | 2020.09.14 |
| matplotlib 기본설정 (한글깨짐, 음수깨짐, 레티나, 테마 지정) (0) | 2020.09.12 |
| python timezone 변경 (0) | 2020.09.10 |
| python 프로젝트 package추가 (내가 만든 패키지 로드) (0) | 2020.09.05 |



댓글